55 | 网络虚拟化:如何成立独立的合作部?





讲述:刘超
时长17:34大小16.09M
上一节,我们讲了存储虚拟化,这一节我们来讲网络虚拟化。
网络虚拟化有和存储虚拟化类似的地方,例如,它们都是基于 virtio 的,因而我们在看网络虚拟化的过程中,会看到和存储虚拟化很像的数据结构和原理。但是,网络虚拟化也有自己的特殊性。例如,存储虚拟化是将宿主机上的文件作为客户机上的硬盘,而网络虚拟化需要依赖于内核协议栈进行网络包的封装与解封装。那怎么实现客户机和宿主机之间的互通呢?我们就一起来看一看。
解析初始化过程
我们还是从 Virtio Network Device 这个设备的初始化讲起。
Virtio Network Device 这种类的定义是有多层继承关系的,TYPE_VIRTIO_NET 的父类是 TYPE_VIRTIO_DEVICE,TYPE_VIRTIO_DEVICE 的父类是 TYPE_DEVICE,TYPE_DEVICE 的父类是 TYPE_OBJECT,继承关系到头了。
type_init 用于注册这种类。这里面每一层都有 class_init,用于从 TypeImpl 生产 xxxClass,也有 instance_init,会将 xxxClass 初始化为实例。
TYPE_VIRTIO_NET 层的 class_init 函数 virtio_net_class_init,定义了 DeviceClass 的 realize 函数为 virtio_net_device_realize,这一点和存储块设备是一样的。
这里面创建了一个 VirtIODevice,这一点和存储虚拟化也是一样的。virtio_init 用来初始化这个设备。VirtIODevice 结构里面有一个 VirtQueue 数组,这就是 virtio 前端和后端互相传数据的队列,最多有 VIRTIO_QUEUE_MAX 个。
刚才我们说的都是一样的地方,其实也有不一样的地方,我们下面来看。
你会发现,这里面有这样的语句 n->max_queues * 2 + 1 > VIRTIO_QUEUE_MAX。为什么要乘以 2 呢?这是因为,对于网络设备来讲,应该分发送队列和接收队列两个方向,所以乘以 2。
接下来,我们调用 virtio_net_add_queue 来初始化队列,可以看出来,这里面就有发送 tx_vq 和接收 rx_vq 两个队列。
每个 VirtQueue 中,都有一个 vring 用来维护这个队列里面的数据;另外还有函数 virtio_net_handle_rx 用于处理网络包的接收;函数 virtio_net_handle_tx_bh 用于网络包的发送,这个函数我们后面会用到。
接下来,qemu_new_nic 会创建一个虚拟机里面的网卡。
qemu 的启动过程中的网络虚拟化
初始化过程解析完毕以后,我们接下来从 qemu 的启动过程看起。
对于网卡的虚拟化,qemu 的启动参数里面有关的是下面两行:
qemu 的 main 函数会调用 net_init_clients 进行网络设备的初始化,可以解析 net 参数,也可以在 net_init_clients 中解析 netdev 参数。
net_init_clients 会解析参数。上面的参数 netdev 会调用 net_init_netdev->net_client_init->net_client_init1。
net_client_init1 会根据不同的 driver 类型,调用不同的初始化函数。
由于我们配置的 driver 的类型是 tap,因而这里会调用 net_init_tap->net_tap_init->tap_open。
在 tap_open 中,我们打开一个文件"/dev/net/tun",然后通过 ioctl 操作这个文件。这是 Linux 内核的一项机制,和 KVM 机制很像。其实这就是一种通过打开这个字符设备文件,然后通过 ioctl 操作这个文件和内核打交道,来使用内核的能力。
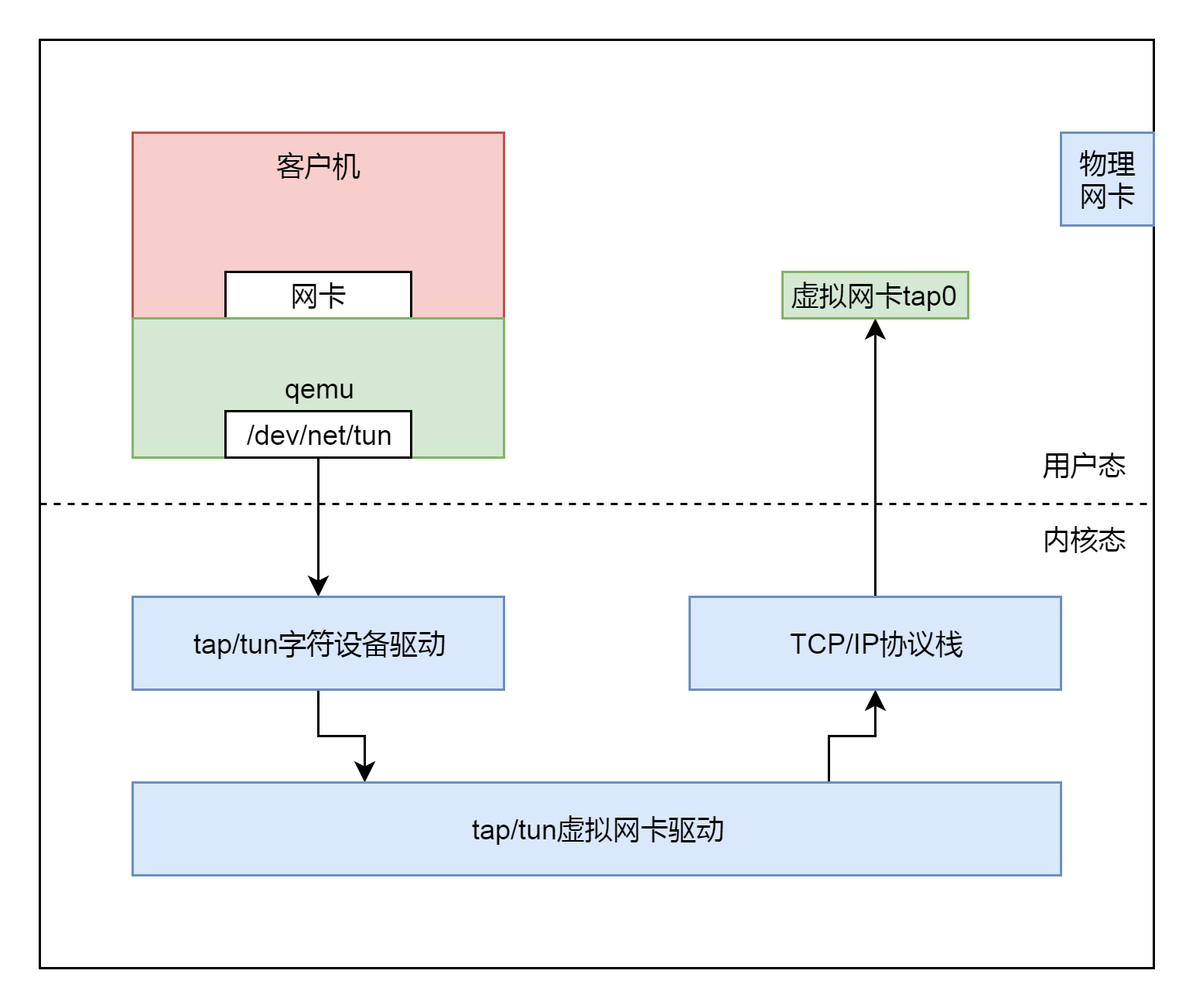
为什么需要使用内核的机制呢?因为网络包需要从虚拟机里面发送到虚拟机外面,发送到宿主机上的时候,必须是一个正常的网络包才能被转发。要形成一个网络包,我们那就需要经过复杂的协议栈,协议栈的复杂咱们在发送网络包那一节讲过了。
客户机会将网络包发送给 qemu。qemu 自己没有网络协议栈,现去实现一个也不可能,太复杂了。于是,它就要借助内核的力量。
qemu 会将客户机发送给它的网络包,然后转换成为文件流,写入"/dev/net/tun"字符设备。就像写一个文件一样。内核中 TUN/TAP 字符设备驱动会收到这个写入的文件流,然后交给 TUN/TAP 的虚拟网卡驱动。这个驱动会将文件流再次转成网络包,交给 TCP/IP 栈,最终从虚拟 TAP 网卡 tap0 发出来,成为标准的网络包。后面我们会看到这个过程。
现在我们到内核里面,看一看打开"/dev/net/tun"字符设备后,内核会发生什么事情。内核的实现在 drivers/net/tun.c 文件中。这是一个字符设备驱动程序,应该符合字符设备的格式。
这里面注册了一个 tun_miscdev 字符设备,从它的定义可以看出,这就是"/dev/net/tun"字符设备。
qemu 的 tap_open 函数会打开这个字符设备 PATH_NET_TUN。打开字符设备的过程我们不再重复。我就说一下,到了驱动这一层,调用的是 tun_chr_open。
在 tun_chr_open 的参数里面,有一个 struct file,这是代表什么文件呢?它代表的就是打开的字符设备文件"/dev/net/tun",因而往这个字符设备文件中写数据,就会通过这个 struct file 写入。这个 struct file 里面的 file_operations,按照字符设备打开的规则,指向的就是 tun_fops。
另外,我们还需要在 tun_chr_open 创建了一个结构 struct tun_file,并且将 struct file 的 private_data 指向它。
在 struct tun_file 中,有一个成员 struct tun_struct,它里面有一个 struct net_device,这个用来表示宿主机上的 tuntap 网络设备。在 struct tun_file 中,还有 struct socket 和 struct sock,因为要用到内核的网络协议栈,所以就需要这两个结构,这在网络协议那一节已经分析过了。
所以,按照 struct tun_file 的注释说的,这是一个很重要的数据结构。"/dev/net/tun"对应的 struct file 的 private_data 指向它,因而可以接收 qemu 发过来的数据。除此之外,它还可以通过 struct sock 来操作内核协议栈,然后将网络包从宿主机上的 tuntap 网络设备发出去,宿主机上的 tuntap 网络设备对应的 struct net_device 也归它管。
在 qemu 的 tap_open 函数中,打开这个字符设备文件之后,接下来要做的事情是,通过 ioctl 来设置宿主机的网卡 TUNSETIFF。
接下来,ioctl 到了内核里面,会调用 tun_chr_ioctl。
在 __tun_chr_ioctl 中,我们首先通过 copy_from_user 把配置从用户态拷贝到内核态,调用 tun_set_iff 设置 tuntap 网络设备,然后调用 copy_to_user 将配置结果返回。
tun_set_iff 创建了 struct tun_struct 和 struct net_device,并且将这个 tuntap 网络设备通过 register_netdevice 注册到内核中。这样,我们就能在宿主机上通过 ip addr 看到这个网卡了。
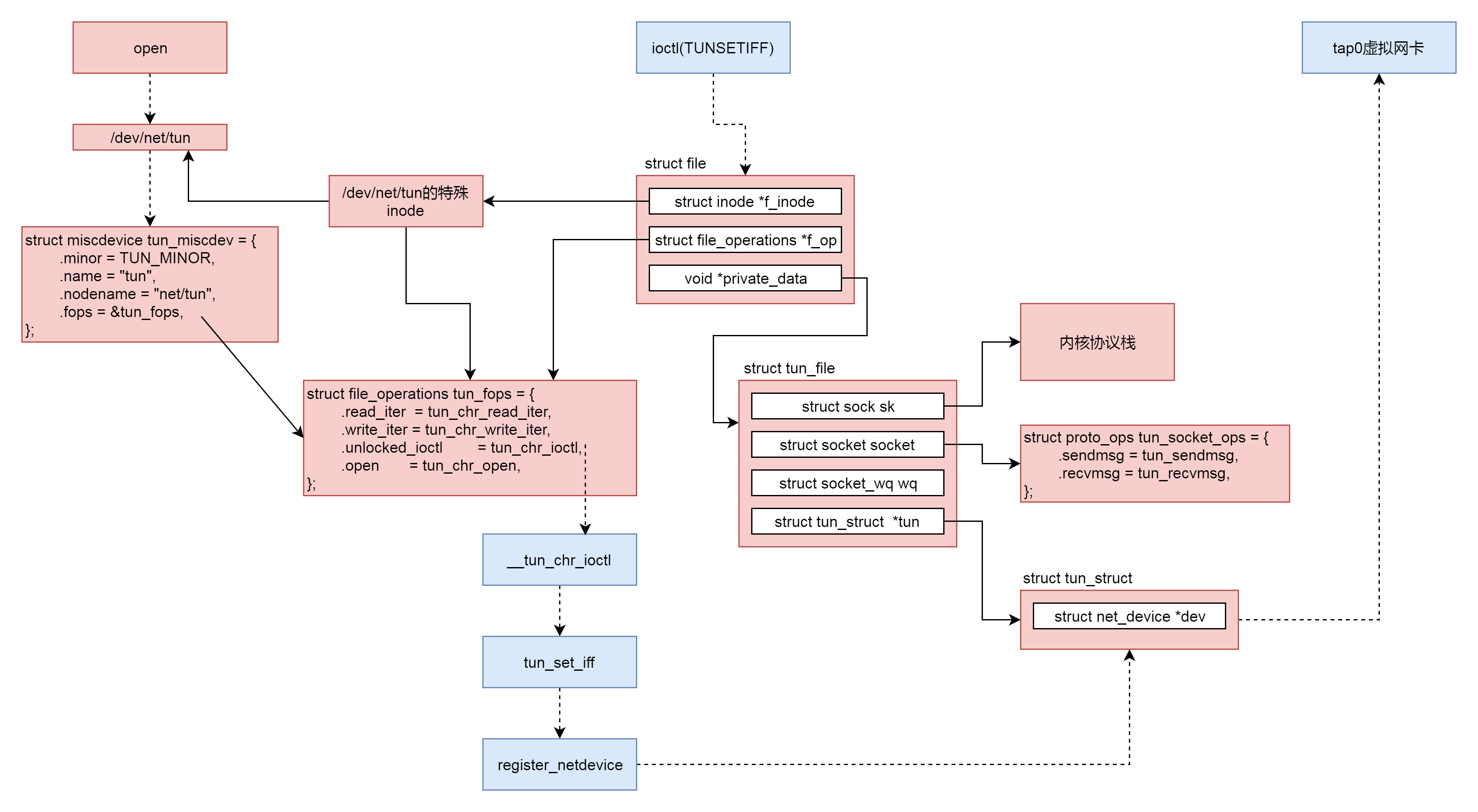
至此宿主机上的内核的数据结构也完成了。
关联前端设备驱动和后端设备驱动
下面,我们来解析在客户机中发送一个网络包的时候,会发生哪些事情。
虚拟机里面的进程发送一个网络包,通过文件系统和 Socket 调用网络协议栈,到达网络设备层。只不过这个不是普通的网络设备,而是 virtio_net 的驱动。
virtio_net 的驱动程序代码在 Linux 操作系统的源代码里面,文件名为 drivers/net/virtio_net.c。
在 virtio_net 的驱动程序的初始化代码中,我们需要注册一个驱动函数 virtio_net_driver。
当一个设备驱动作为一个内核模块被初始化的时候,probe 函数会被调用,因而我们来看一下 virtnet_probe。
在 virtnet_probe 中,会创建 struct net_device,并且通过 register_netdev 注册这个网络设备,这样在客户机里面,就能看到这个网卡了。
在 virtnet_probe 中,还有一件重要的事情就是,init_vqs 会初始化发送和接收的 virtqueue。
按照上一节的 virtio 原理,virtqueue 是一个介于客户机前端和 qemu 后端的一个结构,用于在这两端之间传递数据,对于网络设备来讲有发送和接收两个方向的队列。这里建立的 struct virtqueue 是客户机前端对于队列的管理的数据结构。
队列的实体需要通过函数 virtnet_find_vqs 查找或者生成,这里还会指定接收队列的 callback 函数为 skb_recv_done,发送队列的 callback 函数为 skb_xmit_done。那当 buffer 使用发生变化的时候,我们可以调用这个 callback 函数进行通知。
这里的 find_vqs 是在 struct virtnet_info 里的 struct virtio_device 里的 struct virtio_config_ops *config 里面定义的。
根据 virtio_config_ops 的定义,find_vqs 会调用 vp_modern_find_vqs,到这一步和块设备是一样的了。
在 vp_modern_find_vqs 中,vp_find_vqs 会调用 vp_find_vqs_intx。在 vp_find_vqs_intx 中,通过 request_irq 注册一个中断处理函数 vp_interrupt。当设备向队列中写入信息时,会产生一个中断,也就是 vq 中断。中断处理函数需要调用相应的队列的回调函数,然后根据队列的数目,依次调用 vp_setup_vq 完成 virtqueue、vring 的分配和初始化。
同样,这些数据结构会和 virtio 后端的 VirtIODevice、VirtQueue、vring 对应起来,都应该指向刚才创建的那一段内存。
客户机同样会通过调用专门给外部设备发送指令的函数 iowrite 告诉外部的 pci 设备,这些共享内存的地址。
至此前端设备驱动和后端设备驱动之间的两个收发队列就关联好了,这两个队列的格式和块设备是一样的。
发送网络包过程
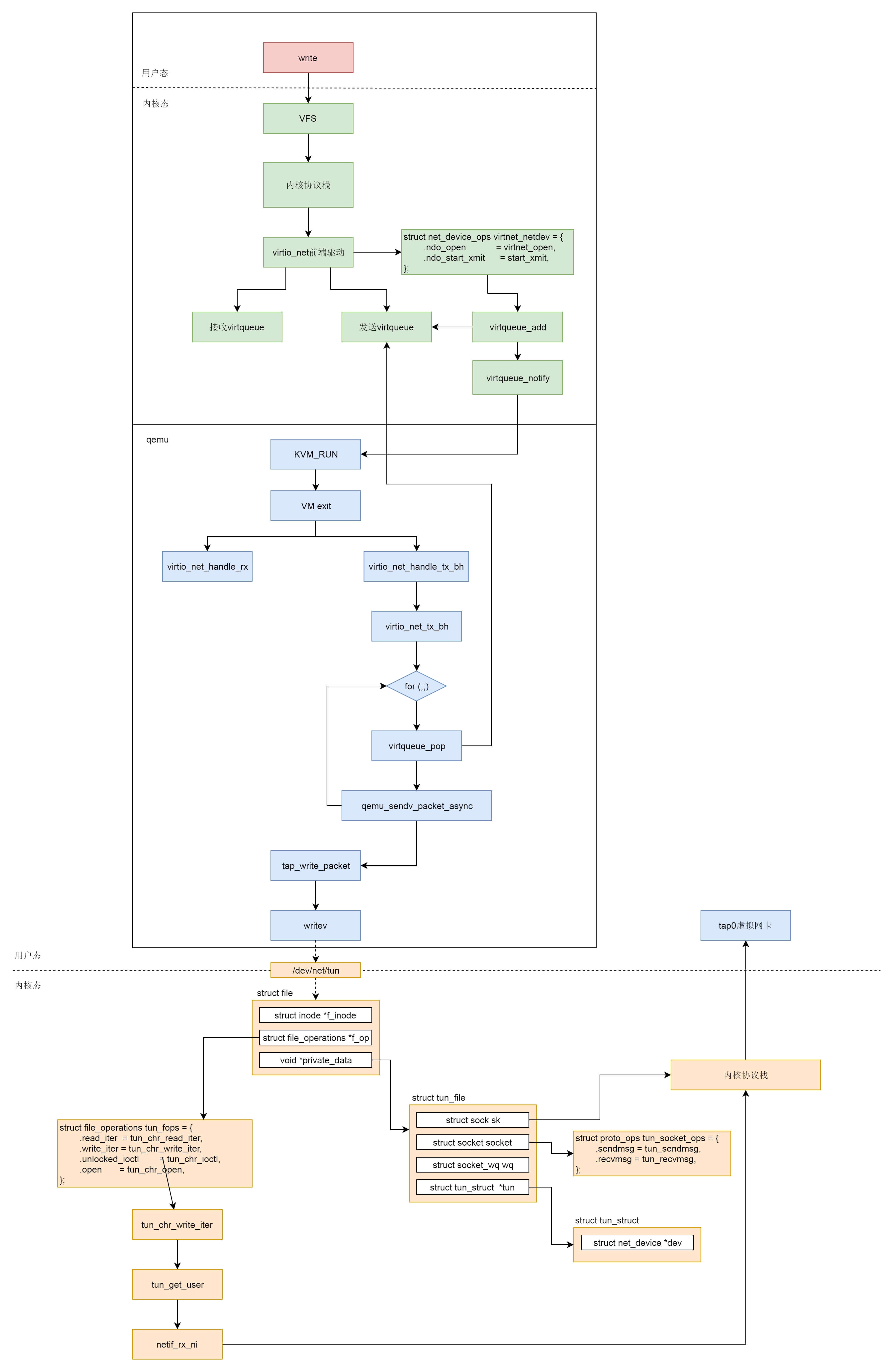
接下来,我们来看当真的发送一个网络包的时候,会发生什么。
当网络包经过客户机的协议栈到达 virtio_net 驱动的时候,按照 net_device_ops 的定义,start_xmit 会被调用。
接下来的调用链为:start_xmit->xmit_skb-> virtqueue_add_outbuf->virtqueue_add,将网络包放入队列中,并调用 virtqueue_notify 通知接收方。
写入一个 I/O 会使得 qemu 触发 VM exit,这个逻辑我们在解析 CPU 的时候看到过。
接下来,我们那会调用 VirtQueue 的 handle_output 函数。前面我们已经设置过这个函数了,其实就是 virtio_net_handle_tx_bh。
virtio_net_handle_tx_bh 调用了 qemu_bh_schedule,而在 virtio_net_add_queue 中调用 qemu_bh_new,并把函数设置为 virtio_net_tx_bh。
virtio_net_tx_bh 函数调用发送函数 virtio_net_flush_tx。
virtio_net_flush_tx 会调用 virtqueue_pop。这里面,我们能看到对于 vring 的操作,也即从这里面将客户机里面写入的数据读取出来。
然后,我们调用 qemu_sendv_packet_async 发送网络包。接下来的调用链为:qemu_sendv_packet_async->qemu_net_queue_send_iov->qemu_net_queue_flush->qemu_net_queue_deliver。
在 qemu_net_queue_deliver 中,我们会调用 NetQueue 的 deliver 函数。前面 qemu_new_net_queue 会把 deliver 函数设置为 qemu_deliver_packet_iov。它会调用 nc->info->receive_iov。
根据 net_tap_info 的定义调用的是 tap_receive_iov。他会调用 tap_write_packet->writev 写入这个字符设备。
在内核的字符设备驱动中,tun_chr_write_iter 会被调用。
当我们使用 writev() 系统调用向 tun/tap 设备的字符设备文件写入数据时,tun_chr_write 函数将被调用。它会使用 tun_get_user,从用户区接收数据,将数据存入 skb 中,然后调用关键的函数 netif_rx_ni(skb) ,将 skb 送给 tcp/ip 协议栈处理,最终完成虚拟网卡的数据接收。
至此,从虚拟机内部到宿主机的网络传输过程才算结束。
总结时刻
最后,我们把网络虚拟化场景下网络包的发送过程总结一下。
- 在虚拟机里面的用户态,应用程序通过 write 系统调用写入 socket。
- 写入的内容经过 VFS 层,内核协议栈,到达虚拟机里面的内核的网络设备驱动,也即 virtio_net。
- virtio_net 网络设备有一个操作结构 struct net_device_ops,里面定义了发送一个网络包调用的函数为 start_xmit。
- 在 virtio_net 的前端驱动和 qemu 中的后端驱动之间,有两个队列 virtqueue,一个用于发送,一个用于接收。然后,我们需要在 start_xmit 中调用 virtqueue_add,将网络包放入发送队列,然后调用 virtqueue_notify 通知 qemu。
- qemu 本来处于 KVM_RUN 的状态,收到通知后,通过 VM exit 指令退出客户机模式,进入宿主机模式。发送网络包的时候,virtio_net_handle_tx_bh 函数会被调用。
- 接下来是一个 for 循环,我们需要在循环中调用 virtqueue_pop,从传输队列中获取要发送的数据,然后调用 qemu_sendv_packet_async 进行发送。
- qemu 会调用 writev 向字符设备文件写入,进入宿主机的内核。
- 在宿主机内核中字符设备文件的 file_operations 里面的 write_iter 会被调用,也即会调用 tun_chr_write_iter。
- 在 tun_chr_write_iter 函数中,tun_get_user 将要发送的网络包从 qemu 拷贝到宿主机内核里面来,然后调用 netif_rx_ni 开始调用宿主机内核协议栈进行处理。
- 宿主机内核协议栈处理完毕之后,会发送给 tap 虚拟网卡,完成从虚拟机里面到宿主机的整个发送过程。
课堂练习
这一节我们解析的是发送过程,请你根据类似的思路,解析一下接收过程。
欢迎留言和我分享你的疑惑和见解,也欢迎收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。

精选留言(3)
 kkxue2019-08-04学了这么多年的虚拟网络,不及老师一节课的深度啊展开
kkxue2019-08-04学了这么多年的虚拟网络,不及老师一节课的深度啊展开 盛2019-08-03学习了:跟完刘老师的趣谈网络协议再跟着linux系统,发现收获又不一样;同时在跟老师的网络协议的过程中,还被迫去跟着学习刘文浩老师的计算机组成原理-否则没法理解老师的一些概念。
盛2019-08-03学习了:跟完刘老师的趣谈网络协议再跟着linux系统,发现收获又不一样;同时在跟老师的网络协议的过程中,还被迫去跟着学习刘文浩老师的计算机组成原理-否则没法理解老师的一些概念。
这大概就是老师之前说的学习方法吧:书阅读越厚、读书的过程中不断去相应的扩展、学习、提升理解,然后整理出自己的东西-书就薄了;虽然书薄了,可是笔记和自己的学习笔录却反而越来越厚了;感谢老师简单形象的教诲。展开 安排2019-08-02网络包是什么样的?经过协议栈处理之前的还是之后的?这样看来虚拟机里面发送网络数据要走两次协议栈吗?因为虚拟机本身也有自己的协议栈,经过虚拟机协议栈处理的数据qemu会进行拆包重新还原出原始的数据吗?展开
安排2019-08-02网络包是什么样的?经过协议栈处理之前的还是之后的?这样看来虚拟机里面发送网络数据要走两次协议栈吗?因为虚拟机本身也有自己的协议栈,经过虚拟机协议栈处理的数据qemu会进行拆包重新还原出原始的数据吗?展开


